F# Data: CSV Type Provider
This article demonstrates how to use the CSV type provider to read CSV files in a statically typed way. This type provider is similar to the one used on the Try F# web site in the "Financial Computing" tutorial, so you can find additional examples there.
The CSV type provider takes a sample CSV as input and generates a type based on the data present on the columns of that sample. The column names are obtained from the first (header) row, and the types are inferred from the values present on the subsequent rows.
Introducing the provider
The type provider is located in the FSharp.Data.dll assembly. Assuming the assembly
is located in the ../../../bin directory, we can load it in F# Interactive as follows:
1: 2: |
#r "../../../bin/FSharp.Data.dll" open FSharp.Data |
Parsing stock prices
The Yahoo Finance web site provides daily stock prices in a CSV format that has the
following structure (you can find a larger example in the data/MSFT.csv file):
Date,Open,High,Low,Close,Volume,Adj Close
2012-01-27,29.45,29.53,29.17,29.23,44187700,29.23
2012-01-26,29.61,29.70,29.40,29.50,49102800,29.50
2012-01-25,29.07,29.65,29.07,29.56,59231700,29.56
2012-01-24,29.47,29.57,29.18,29.34,51703300,29.34
As usual with CSV files, the first row contains the headers (names of individual columns)
and the next rows define the data. We can pass reference to the file to CsvProvider to
get a strongly typed view of the file:
1:
|
type Stocks = CsvProvider<"../data/MSFT.csv"> |
The generated type provides two static methods for loading data. The Parse method can be
used if we have the data in a string value. The Load method allows reading the data from
a file or from a web resource (and there's also an asynchronous AsyncLoad version). We could also
have used a web url instead of a local file in the sample parameter of the type provider.
The following sample calls the Load method with an URL that points to a live CSV file on the Yahoo finance web site:
1: 2: 3: 4: 5: 6: 7: 8: 9: 10: 11: 12: |
// Download the stock prices let msft = Stocks.Load("http://ichart.finance.yahoo.com/table.csv?s=MSFT") // Look at the most recent row. Note the 'Date' property // is of type 'DateTime' and 'Open' has a type 'decimal' let firstRow = msft.Rows |> Seq.head let lastDate = firstRow.Date let lastOpen = firstRow.Open // Print the prices in the HLOC format for row in msft.Rows do printfn "HLOC: (%A, %A, %A, %A)" row.High row.Low row.Open row.Close |
The generated type has a property Rows that returns the data from the CSV file as a
collection of rows. We iterate over the rows using a for loop. As you can see the
(generated) type for rows has properties such as High, Low and Close that correspond
to the columns in the CSV file.
As you can see, the type provider also infers types of individual rows. The Date
property is inferred to be a DateTime (because the values in the sample file can all
be parsed as dates) while HLOC prices are inferred as decimal.
Charting stock prices
We can use the FSharp.Charting library to draw a simple line chart showing how the price of MSFT stocks changes since the company was founded:
1: 2: 3: 4: |
// Load the FSharp.Charting library #load "../../../packages/FSharp.Charting.0.90.6/FSharp.Charting.fsx" open System open FSharp.Charting |
1: 2: 3: |
// Visualize the stock prices [ for row in msft.Rows -> row.Date, row.Open ] |> Chart.FastLine |
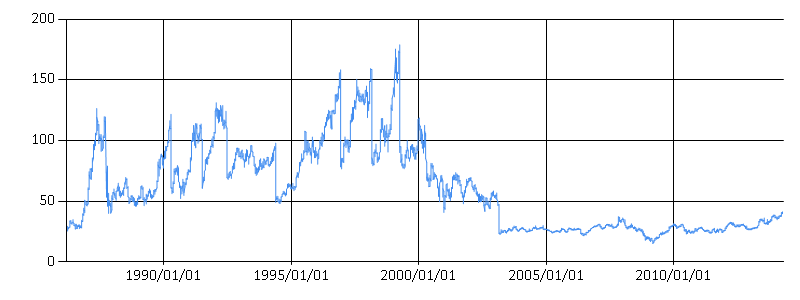
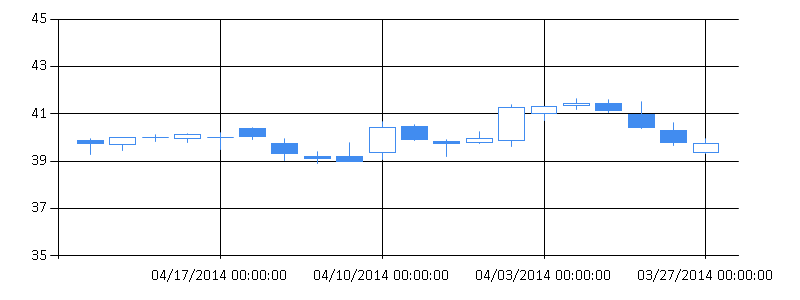
As a one more example, we use the Candlestick chart to get a more detailed look at the
data over the last month:
1: 2: 3: 4: 5: |
// Get last months' prices in HLOC format let recent = [ for row in msft.Rows do if row.Date > DateTime.Now.AddDays(-30.0) then yield row.Date, row.High, row.Low, row.Open, row.Close ] |
1: 2: |
// Visualize prices using Candlestick chart Chart.Candlestick(recent).WithYAxis(Min = 35.0, Max = 45.0) |
Using units of measure
Another interesting feature of the CSV type provider is that it supports F# units of measure. If the header includes the name or symbol of one of the standard SI units, then the generated type returns values annotated with the appropriate unit.
In this section, we use a simple file data/SmallTest.csv which
looks as follows:
Name, Distance (metre), Time (s)
First, 50.0, 3.7
As you can see, the second and third columns are annotated with metre and s,
respectively. To use units of measure in our code, we need to open the namespace with
standard unit names. Then we pass the SmallTest.csv file to the type provider as
a static argument. Also note that in this case we're using the same data at runtime,
so we use the GetSample method instead of calling Load and passing the same parameter again.
1:
|
let small = CsvProvider<"../data/SmallTest.csv">.GetSample() |
We can also use the default constructor instead of the GetSample static method:
1:
|
let small2 = new CsvProvider<"../data/SmallTest.csv">() |
but the VisualStudio intellisense for the type provider parameters doesn't work when we use a default
constructor for a type provider, so we'll keep using GetSample instead.
As in the previous example, the small value exposes the rows using the Rows property.
The generated properties Distance and Time are now annotated with units. Look at the
following simple calculation:
1: 2: 3: 4: 5: 6: |
open Microsoft.FSharp.Data.UnitSystems.SI.UnitNames for row in small.Rows do let speed = row.Distance / row.Time if speed > 15.0M<metre/second> then printfn "%s (%A m/s)" row.Name speed |
The numerical values of Distance and Time are both inferred as decimal (because they
are small enough). Thus the type of speed becomes decimal<meter/second>. The compiler
can then statically check that we're not comparing incompatible values - e.g. number in
meters per second against a value in kilometres per hour.
Custom separators and tab-separated files
By default, the CSV type provider uses comma (,) as a separator. However, CSV
files sometime use a different separator character than ,. In some European
countries, , is already used as the numeric decimal separator, so a semicolon (;) is used
instead to separate CSV columns. The CsvProvider has an optional Separator static parameter
where you can specify what to use as separator. This means that you can consume
any textual tabular format. Here is an example using ; as a separator:
1: 2: 3: 4: 5: |
let airQuality = new CsvProvider<"../data/AirQuality.csv", ";">() for row in airQuality.Rows do if row.Month > 6 then printfn "Temp: %i Ozone: %f " row.Temp row.Ozone |
The air quality dataset (data/AirQuality.csv) is used in many
samples for the Statistical Computing language R. A short description of the dataset can be found
in the R language manual.
If you are parsing a tab-separated file that uses \t as the separator, you can also
specify the separator explicitly. However, if you're using an url or file that has
the .tsv extension, the type provider will use \t by default. In the following example,
we also set IgnoreErrors static parameter to true so that lines with incorrect number of elements
are automatically skipped (the sample file (data/MortalityNY.csv) contains additional unstructured data at the end):
1: 2: 3: 4: 5: 6: 7: 8: 9: 10: 11: 12: |
let mortalityNy = CsvProvider<"../data/MortalityNY.tsv", IgnoreErrors=true>.GetSample() // Find the name of a cause based on code // (Pedal cyclist injured in an accident) let cause = mortalityNy.Rows |> Seq.find (fun r -> r.``Cause of death Code`` = "V13.4") // Print the number of injured cyclists printfn "CAUSE: %s" cause.``Cause of death`` for r in mortalityNy.Rows do if r.``Cause of death Code`` = "V13.4" then printfn "%s (%d cases)" r.County r.Count |
Finally, note that it is also possible to specify multiple different separators
for the CsvProvider. This might be useful if a file is irregular and contains
rows separated by either semicolon or a colon. You can use:
CsvProvider<"../data/AirQuality.csv", Separator=";,">.
Missing values
It is quite common in statistical datasets for some values to be missing. If
you open the data/AirQuality.csv file you will see
that some values for the Ozone observations are marked #N/A. Such values are
parsed as float and will in F# be marked with Double.NaN. The values #N/A, NA,
and : are recognized as missing values by default, but you can customize it by specifying
the MissingValues static parameter of CsvProvider.
The following snippet calculates the mean of the ozone observations
excluding the Double.NaN values. We first obtain the Ozone property for
each row, then remove missing values and then use the standard Seq.average function:
1: 2: 3: 4: 5: |
let mean = airQuality.Rows |> Seq.map (fun row -> row.Ozone) |> Seq.filter (fun elem -> not (Double.IsNaN elem)) |> Seq.average |
If the sample doesn't have missing values on all columns, but at runtime missing values could
appear anywhere, you can set the static parameter AssumeMissingValues to true in order to force CsvProvider
to assume missing values can occur in any column.
Controlling the column types
By default, the CSV type provider checks the first 1000 rows to infer the types, but you can customize
it by specifying the InferRows static parameter of CsvProvider. If you specify 0 the entire file will be used.
Columns with only 0, 1, Yes, No, True, or False will be set to bool. Columns with numerical values
will be set to either int, int64, decimal, or float, in that order of preference.
If in any row a value is missing, by default the CSV type provider will infer a nullable (for int and int64) or an optional
(for bool, DateTime and Guid). When a decimal would be inferred but there are missing values, we will infer a
float instead, and use Double.NaN to represent those missing values. The string type is already inherently nullable,
so by default we won't generate a string option. If you prefer to use optionals in all cases, you can set the static parameter
PreferOptionals to true. In that case you'll never get an empty string or a Double.NaN and will always get a None instead.
If you have other preferences, e.g. if you want a column to be a float instead of a decimal,
you can override the default behaviour by specifying the types in the header column between braces, similar to what can be done to
specify the units of measure. This will override both AssumeMissingValues and PreferOptionals. The valid types are:
intint?int optionint64int64?int64 optionboolbool?bool optionfloatfloat?float optiondecimaldecimal?decimal optiondatedate?date optionguidguid?guid optionstringstring option.
You can also specify both the type and a unit (e.g float<metre>). Example:
Name, Distance (decimal?<metre>), Time (float)
First, 50, 3
Additionally, you can also specify some or all the types in the Schema static parameter of CsvProvider. Valid formats are:
TypeType<Measure>Name (Type)Name (Type<Measure>)
What's specified in the Schema static parameter will always take precedence to what's specified in the column headers.
If the first row of the file is not a header row, you can specify the HasHeaders static parameter to false in order to
consider that row as a data row. In that case, the columns will be named Column1, Column2, etc..., unless the
names are overridden using the Schema parameter. Note that you can override only the name in the Schema parameter
and still have the provider infer the type for you. Example:
1: 2: 3: |
let csv = CsvProvider<"1,2,3", HasHeaders = false, Schema = "Duration (float<second>),foo,float option">.GetSample() for row in csv.Rows do printfn "%f %d %f" (row.Duration/1.0<second>) row.foo (defaultArg row.Column3 1.0) |
You don't need to override all the columns, you can skip the ones to leave as default.
For example, in the titanic training dataset from Kaggle (data/Titanic.csv),
if you want to rename the 3rd column (the PClass column) to Passenger Class and override the
6th column (the Fare column) to be a float instead of a decimal, you can define only that, and leave
the other columns blank in the schema (you also don't need to add all the trailing commas).
1: 2: 3: |
let titanic1 = CsvProvider<"../data/Titanic.csv", Schema=",,Passenger Class,,,float">.GetSample() for row in titanic1.Rows do printfn "%s Class = %d Fare = %g" row.Name row.``Passenger Class`` row.Fare |
Alternatively, you can rename and override the type of any column by name instead of by position:
1: 2: 3: |
let titanic2 = CsvProvider<"../data/Titanic.csv", Schema="Fare=float,PClass->Passenger Class">.GetSample() for row in titanic2.Rows do printfn "%s Class = %d Fare = %g" row.Name row.``Passenger Class`` row.Fare |
You can even mix and match the two syntaxes like this Schema="int64,DidSurvive,PClass->Passenger Class=string"
Transforming CSV files
In addition to reading, CsvProvider also has support for transforming CSV files. The operations
available are Filter, Take, TakeWhile, Skip, SkipWhile, and Truncate. All these operations
preserve the schema, so after transforming you can save the results by using one of the overloads of
the Save method. If you don't need to save the results in the CSV format, or if your transformations
need to change the shape of the data, you can also use the operations available in the Seq module on the the
sequence of rows exposed via the Rows property directly.
1: 2: 3: 4: 5: |
// Saving the first 10 rows that don't have missing values to a new csv file airQuality.Filter(fun row -> not (Double.IsNaN row.Ozone) && not (Double.IsNaN row.``Solar.R``)) .Truncate(10) .SaveToString() |
Handling big datasets
By default, the rows are cached so you can iterate over the Rows property multiple times without worrying.
But if you will only iterate once, you can disable caching by settting the CacheRows static parameter of CsvProvider
to false . If the number of rows is very big, you have to do this otherwise you may exhaust the memory.
You can still cache the data at some point by using the Cache method, but only do that if you have already
transformed the dataset to be smaller:
1: 2: |
let stocks = CsvProvider<"http://ichart.finance.yahoo.com/table.csv?s=MSFT", CacheRows=false>.GetSample() stocks.Take(10).Cache() |
Related articles
- F# Data: CSV Parser and Reader - provides more information about working with CSV documents dynamically.
- API Reference: CsvProvider type provider
Full name: CsvProvider.Stocks
Full name: FSharp.Data.CsvProvider
<summary>Typed representation of a CSV file.</summary>
<param name='Sample'>Location of a CSV sample file or a string containing a sample CSV document.</param>
<param name='Separators'>Column delimiter(s). Defaults to `,`.</param>
<param name='Culture'>The culture used for parsing numbers and dates. Defaults to the invariant culture.</param>
<param name='InferRows'>Number of rows to use for inference. Defaults to `1000`. If this is zero, all rows are used.</param>
<param name='Schema'>Optional column types, in a comma separated list. Valid types are `int`, `int64`, `bool`, `float`, `decimal`, `date`, `guid`, `string`, `int?`, `int64?`, `bool?`, `float?`, `decimal?`, `date?`, `guid?`, `int option`, `int64 option`, `bool option`, `float option`, `decimal option`, `date option`, `guid option` and `string option`.
You can also specify a unit and the name of the column like this: `Name (type<unit>)`, or you can override only the name. If you don't want to specify all the columns, you can reference the columns by name like this: `ColumnName=type`.</param>
<param name='HasHeaders'>Whether the sample contains the names of the columns as its first line.</param>
<param name='IgnoreErrors'>Whether to ignore rows that have the wrong number of columns or which can't be parsed using the inferred or specified schema. Otherwise an exception is thrown when these rows are encountered.</param>
<param name='AssumeMissingValues'>When set to true, the type provider will assume all columns can have missing values, even if in the provided sample all values are present. Defaults to false.</param>
<param name='PreferOptionals'>When set to true, inference will prefer to use the option type instead of nullable types, `double.NaN` or `""` for missing values. Defaults to false.</param>
<param name='Quote'>The quotation mark (for surrounding values containing the delimiter). Defaults to `"`.</param>
<param name='MissingValues'>The set of strings recogized as missing values. Defaults to `NaN,NA,#N/A,:,-`.</param>
<param name='CacheRows'>Whether the rows should be caches so they can be iterated multiple times. Defaults to true. Disable for large datasets.</param>
<param name='ResolutionFolder'>A directory that is used when resolving relative file references (at design time and in hosted execution).</param>
Full name: CsvProvider.msft
Loads CSV from the specified uri
CsvProvider<...>.Load(reader: System.IO.TextReader) : CsvProvider<...>
Loads CSV from the specified reader
CsvProvider<...>.Load(stream: System.IO.Stream) : CsvProvider<...>
Loads CSV from the specified stream
Full name: CsvProvider.firstRow
from Microsoft.FSharp.Collections
Full name: Microsoft.FSharp.Collections.Seq.head
Full name: CsvProvider.lastDate
Full name: CsvProvider.lastOpen
Full name: Microsoft.FSharp.Core.ExtraTopLevelOperators.printfn
static member Area : data:seq<#value> * ?Name:string * ?Title:string * ?Labels:#seq<string> * ?Color:Color * ?XTitle:string * ?YTitle:string -> GenericChart
static member Area : data:seq<#key * #value> * ?Name:string * ?Title:string * ?Labels:#seq<string> * ?Color:Color * ?XTitle:string * ?YTitle:string -> GenericChart
static member Bar : data:seq<#value> * ?Name:string * ?Title:string * ?Labels:#seq<string> * ?Color:Color * ?XTitle:string * ?YTitle:string -> GenericChart
static member Bar : data:seq<#key * #value> * ?Name:string * ?Title:string * ?Labels:#seq<string> * ?Color:Color * ?XTitle:string * ?YTitle:string -> GenericChart
static member BoxPlotFromData : data:seq<#key * #seq<'a2>> * ?Name:string * ?Title:string * ?Color:Color * ?XTitle:string * ?YTitle:string * ?Percentile:int * ?ShowAverage:bool * ?ShowMedian:bool * ?ShowUnusualValues:bool * ?WhiskerPercentile:int -> GenericChart (requires 'a2 :> value)
static member BoxPlotFromStatistics : data:seq<#key * #value * #value * #value * #value * #value * #value> * ?Name:string * ?Title:string * ?Labels:#seq<string> * ?Color:Color * ?XTitle:string * ?YTitle:string * ?Percentile:int * ?ShowAverage:bool * ?ShowMedian:bool * ?ShowUnusualValues:bool * ?WhiskerPercentile:int -> GenericChart
static member Bubble : data:seq<#value * #value> * ?Name:string * ?Title:string * ?Labels:#seq<string> * ?Color:Color * ?XTitle:string * ?YTitle:string * ?BubbleMaxSize:int * ?BubbleMinSize:int * ?BubbleScaleMax:float * ?BubbleScaleMin:float * ?UseSizeForLabel:bool -> GenericChart
static member Bubble : data:seq<#key * #value * #value> * ?Name:string * ?Title:string * ?Labels:#seq<string> * ?Color:Color * ?XTitle:string * ?YTitle:string * ?BubbleMaxSize:int * ?BubbleMinSize:int * ?BubbleScaleMax:float * ?BubbleScaleMin:float * ?UseSizeForLabel:bool -> GenericChart
static member Candlestick : data:seq<#value * #value * #value * #value> * ?Name:string * ?Title:string * ?Labels:#seq<string> * ?Color:Color * ?XTitle:string * ?YTitle:string -> CandlestickChart
static member Candlestick : data:seq<#key * #value * #value * #value * #value> * ?Name:string * ?Title:string * ?Labels:#seq<string> * ?Color:Color * ?XTitle:string * ?YTitle:string -> CandlestickChart
...
Full name: FSharp.Charting.Chart
static member Chart.FastLine : data:seq<#key * #value> * ?Name:string * ?Title:string * ?Labels:#seq<string> * ?Color:Drawing.Color * ?XTitle:string * ?YTitle:string -> ChartTypes.GenericChart
Full name: CsvProvider.recent
type DateTime =
struct
new : ticks:int64 -> DateTime + 10 overloads
member Add : value:TimeSpan -> DateTime
member AddDays : value:float -> DateTime
member AddHours : value:float -> DateTime
member AddMilliseconds : value:float -> DateTime
member AddMinutes : value:float -> DateTime
member AddMonths : months:int -> DateTime
member AddSeconds : value:float -> DateTime
member AddTicks : value:int64 -> DateTime
member AddYears : value:int -> DateTime
...
end
Full name: System.DateTime
--------------------
DateTime()
(+0 other overloads)
DateTime(ticks: int64) : unit
(+0 other overloads)
DateTime(ticks: int64, kind: DateTimeKind) : unit
(+0 other overloads)
DateTime(year: int, month: int, day: int) : unit
(+0 other overloads)
DateTime(year: int, month: int, day: int, calendar: Globalization.Calendar) : unit
(+0 other overloads)
DateTime(year: int, month: int, day: int, hour: int, minute: int, second: int) : unit
(+0 other overloads)
DateTime(year: int, month: int, day: int, hour: int, minute: int, second: int, kind: DateTimeKind) : unit
(+0 other overloads)
DateTime(year: int, month: int, day: int, hour: int, minute: int, second: int, calendar: Globalization.Calendar) : unit
(+0 other overloads)
DateTime(year: int, month: int, day: int, hour: int, minute: int, second: int, millisecond: int) : unit
(+0 other overloads)
DateTime(year: int, month: int, day: int, hour: int, minute: int, second: int, millisecond: int, kind: DateTimeKind) : unit
(+0 other overloads)
static member Chart.Candlestick : data:seq<#key * #value * #value * #value * #value> * ?Name:string * ?Title:string * ?Labels:#seq<string> * ?Color:Drawing.Color * ?XTitle:string * ?YTitle:string -> ChartTypes.CandlestickChart
Full name: CsvProvider.small
Full name: CsvProvider.small2
type metre
Full name: Microsoft.FSharp.Data.UnitSystems.SI.UnitNames.metre
type second
Full name: Microsoft.FSharp.Data.UnitSystems.SI.UnitNames.second
Full name: CsvProvider.airQuality
Full name: CsvProvider.mortalityNy
Full name: CsvProvider.cause
Full name: Microsoft.FSharp.Collections.Seq.find
Full name: CsvProvider.mean
Full name: Microsoft.FSharp.Collections.Seq.map
Full name: Microsoft.FSharp.Collections.Seq.filter
Full name: Microsoft.FSharp.Core.Operators.not
struct
member CompareTo : value:obj -> int + 1 overload
member Equals : obj:obj -> bool + 1 overload
member GetHashCode : unit -> int
member GetTypeCode : unit -> TypeCode
member ToString : unit -> string + 3 overloads
static val MinValue : float
static val MaxValue : float
static val Epsilon : float
static val NegativeInfinity : float
static val PositiveInfinity : float
...
end
Full name: System.Double
Full name: Microsoft.FSharp.Collections.Seq.average
Full name: CsvProvider.csv
Full name: Microsoft.FSharp.Core.Operators.defaultArg
Full name: CsvProvider.titanic1
Full name: CsvProvider.titanic2
Full name: CsvProvider.stocks


